株式会社ログラスの松岡(@little_hand_s)です。
最近、値オブジェクトに関して書かれているブログ記事を見ますが、 SNSなどにおいてDDDにおける値オブジェクトについて誤解されているような反応が見受けられました。
そこで、この記事では「DDDにおける値オブジェクトの位置付け」について解説し、具体的なモデル・コードを用いながら誤解を解いていきたいと思います。
なお、値オブジェクトに関する詳細な説明はここでは行いませんのでご了承下さい。
DDDの目的
まず最初に、DDDの目的について確認します。
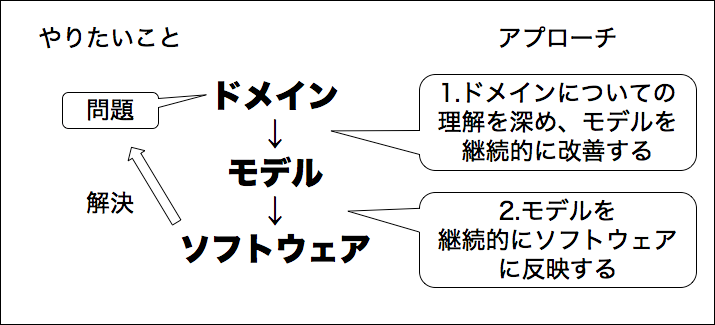
DDDの目的は、モデリングを通じてソフトウェアの価値を大きくすることです。
これに関しては、こちらの記事で詳細に解説しているのでこちらをご覧ください。
ドメイン駆動設計は何を解決しようとしているのか - little hands' lab
ここで大切なのは、モデルは一回のモデリングで完成形に至ることはほとんどなく、継続的なフィードバックの機会を作り、継続的に改善していくことが必要だということです。(これはエヴァンス本ではドメインエキスパートと一緒にモデルを「探求する」と表現されています)
DDDのコードに求められること
モデルを継続的に改善し続けることになれば、自ずとその変更をソフトウェアに反映し続ける必要が発生します。
そのために、モデルとコードの形をある程度一致させることが重要になります。 モデルとコードの形が乖離していると、どこに反映したらいいのか迷ったり、反映しようとしてミスが発生する要因になったりするためです。
また、継続的な変更を反映し続けられるだけの高い保守性も同時に求められます。
そこで、上記のような目的においてある程度実績のあるベストプラクティスのようなものがエンティティ、値オブジェクト、リポジトリ…といったDDDの実装パターンです。
つまり!!
エンティティ、値オブジェクトなどを使うことは目的でもルールでも制約でもなく、 頻繁にモデルを改善し、それをコードに反映し続けるための手段なのです。
DDDと値オブジェクトのよくある誤解
よくある誤解①
DDDでは全ての属性を値オブジェクトにしないといけない
大きな誤解です。
前述の目的を踏まえると、こんな制約などないことがわかるでしょう。もしあったとすると、それはあくまでそのルールを採用している現場固有の規約です。*1
メリットデメリットを考慮し、メリットの方が大きい時に使いましょう。
よくある誤解②
DDDのドメイン層ではエンティティ、値オブジェクトしか使ってはいけない
そんなことはありません、enum、ファーストクラスコレクションといった実装パターンはよく併用します。
あくまで「エンティティ、値オブジェクトみたいなパターンを使うと上手く表現できるよ」というプラクティスが存在しているだけで、「〜しかしてはいけない」というルールはありません。
よくある誤解③
DDDはオブジェクト指向でなければならない。
(≒ので、関数型の時代にはそぐわない)
これは実現方法の選択の問題です。
エヴァンス本が書かれた時代にベストだと考えられたものはオブジェクト指向であり、現代でも十分に通用する方法だと思っています。(筆者の現場ではそのように実装し、十分な成果を得られています)
ただし、エヴァンス本が書かれた時代からは選択肢は言語、設計手法、フレームワークなど選択肢は広がっています。実際、海外ではイベントソーシングを用いた手法がトレンドになっています。
「頻繁にモデルを改善し、それをコードに反映し続ける」という目的において最適な選択肢を探求することは重要なことです。是非やっていきましょう。
「モデルとコードの形をある程度一致させる」とはどういうことか
先述の、「モデルとコードの形をある程度一致させる」とはどういうことか、論よりコード*2、ということでモデルとコードの実例で説明しましょう。
題材
ユーザーとメールアドレスが必要な場合についてモデリングし、コードまで落としてみます。 これは説明のための事例なので、何のユーザーなのかといった点、そのネーミング、制約などのモデリング内容に関する是非は一旦置いておきます。 モデルとコードの対比のみに注目いただければと思います。
モデリングの例
それでは、オブジェクト図、ドメインモデル図を使ってモデリングしてみます。*3
まず、具体例を書き出すオブジェクト図を作成している際、ドメインエキスパートとエンジニアの議論により、このような内容が書き出されました。

件数制限に関しては後回し…というのは実際にモデリングする際にありそうな例を意図的に書いています。ここは保留にして、一段階抽象化した成果としてのドメインモデル図が以下のようになりました。

モデルと乖離したコード
最初に、敢えて「ドメインモデルと乖離した」コードを先に書いてみます。
先ほどのドメインモデルを、テーブル構造と1対1になるようなORマッパーのクラスで実装するとどうなるでしょう。 (これは架空のORマッパーをイメージしていますので文法などの細かい話は無視してください)
メールアドレスを持つテーブルは、他にも子テーブルとしてメールアドレスを持つテーブルが作られる可能性があるため、mail_addresses テーブルではなくuser_mail_addresses テーブルという命名としました。それに対応したクラスは以下のようになります。言語はKotlinです。
@Table(tableName = "users") class User( var userId: String, var name: String, @OneToMany var mailAddresses: List<UserMailAddress> // ① ){ // mailAddressesを操作する処理は省略 } @Table(tableName = "user_mail_addresses") class UserMailAddress( var userMailAddressId: String, @ManyToOne var user: User, // ② var mailAddress: String ) { init { // 書式のバリデーションを実装する } }
ユーザーに紐づくメールアドレスのテーブルと対応するため、UserMailAddress クラスは②のように親クラスを参照し、①で相互参照になっています。 また、UserMailAddressIdはライブラリのデフォルト挙動として生成されているイメージです。 このような実装はOR マッパーによって異なりますが、ポピュラーなORマッパーでみられる実装です。
このコードでは、クラス名、保持する属性、参照方向などがドメインモデル図との乖離が生まれており、UserMailAddress クラス単体で何を表すのか若干わかりにくくなります。
これが、「モデルとコードの乖離」です。
このようなずれは、ドメインモデルが複雑になるほど大きくなっていきます。
ただし、これが常に問題だ!!ということはありません。
前述の通り、たとえ乖離しても、モデルの進化に追従可能で、保守性がそれなりに高ければ問題はありません。 問題がなければ、敢えてエンティティ、値オブジェクトといったパターンを導入する必要はないのです。
ですが、もし導入してみてメリットがあるのであれば、デメリットを考慮しながら導入検討してみると良いでしょう。 ここには、実践者が自分の意思で選択する余地があります。
モデルとコードの形が一致したコード
それでは、メリットデメリットを検討する材料として、ドメインモデルを極力そのままの形でコードに落としたコードを示してみましょう。
class User( val userId: String, val name: String, val mailAddresses: MutableList<MailAddress> ) { // mailAddressesを操作する処理は省略 } data class MailAddress(val value: String) { init { // 書式のバリデーションを実装する } }
改めてドメインモデル図と見比べると、それぞれのクラスの名前、保持している情報が同じで、モデル図の形を維持していることがわかります。 これで、モデル図に変更があっても、反映先を迷いにくくなります。
コードとしての影響はどうでしょうか。 (IDに型を持たせる要否や、MutableList型をそのまま公開する是非など検討ポイントがありますが、本記事における論点はそこではないのでここでは置いておきます)
先のコードに比べると、MailAddressクラスの変更は以下の通りです。
① 名前がUserMailAddressではなくモデル図と同じMailAddressになった
②Userクラスへの参照を持たなくなり、属性がメールアドレスの値だけになった
③識別子がなくなった
④イミュータブルになった
①〜③の変更により、MailAddressクラスの責務(何を表すクラスか)が明確になり、保持する属性、メソッドとの関連性が高まりました。つまり、高凝集になりました。 一般に、高凝集/低結合にすると保守性が高まりやすいです。*4
また、②により、MailAddressクラス単独でユニットテストを書きやすくなりました。先述のコードの場合、UserMailAddressクラスの書式チェックのユニットテストを書く場合に、関係のないUserインスタンスが必要になりました。それに比べると、テスト容易性が向上しています。
また、プロジェクトの他の場所でメールアドレスを使用したい際にも、問題なく再利用できるコードになりました。
改めて、値オブジェクトの位置付け
実は、③④を満たしたことによって値オブジェクトの条件を満たした*5のですが、モデルと形を一致させ、保守性改善に大きく寄与しているのは①〜③です。 ここではMailAddressクラスにIDクラスは不要であり、イミュータブルにする理由もないので、結果として値オブジェクトになっているぐらいです。。
こんなもんです!値オブジェクトかどうかという重要性は。
それよりはとにかく「モデルとコードを極力一致させる」「高凝集/低結合」を目指す方がシンプルかつ、重要です。 その上で、実装中に値オブジェクトというパターンを使えたら使おう、ぐらいの気持ちでOKです。
まとめ
改善した感じのサンプルコードを出しましたが、「常にこうしろ」というわけではありません。 このような方法を導入するメリットデメリットを検討し、必要であれば導入すれば良いのです。 その検討、判断を自分でするということが重要です。
目的の理解を抜きにして「〜べき」「〜べからす」に振り回されてしまうのは辛いものです。 何事もそうですが、目的を理解することによって、手段の位置付けを上手く把握することができます。
もっと色々知りたくなったら
本記事のサンプルコードは2021年10月発売の解説書「ドメイン駆動設計FAQ&サンプルコード 3.1.1 データモデルやOR マッパークラスとの違い」から抜粋したものを、ブログ記事の趣旨に合わせて加筆したものです。
本書は重要トピック「モデリング」「集約」「テスト」について詳細に解説し、その他のトピックでは頻出の質問への回答と具体的なサンプルコードをふんだんに盛り込みました。現場で実践して、困っていることがある方はぜひこちらもご覧ください。
また、DDD自体に関する解説はこちらもご覧ください。
初めてDDDを学ぶ方、もしくは実際に着手して難しさにぶつかっている方向けの書籍です。 迷子になりがちな「DDDの目的」や「モデル」の解説からはじめ、具体的なモデリングを行い実装まで落とす事例を元に、DDDの魅力や効果を体感することを目指します。
現場での導入で困ったら
DDDを導入しようとすると結構試行錯誤に時間がかかります。
現場で導入してすぐに効果を発揮したい!!という方向けに、基礎解説とライブモデリング/コーディングを行う勉強会の開催や、設計相談を受付ております。
事例紹介もあるのでご関心あれば覗いてみてください。開催形式は柔軟に対応できるのでお気軽にご相談ください。
その他関連記事
また、エンティティ、値オブジェクトについてはこちらに記事があります。
YouTubeで10分でわかるDDD動画シリーズをアップしています。概要を動画で理解したい方はこちらもご覧ください。。チャンネル登録すると新しい動画の通知を受け取ることができます。